Voice-To-Voice AI: The Next Frontier
10x better voice agents, 10x cheaper in cost.

As I send this out, I promised to attach a code sample of a quick voice to voice customer support demo I put together with Gemini’s Flash 2.0 model. Here is the code for that demo, for folks who’d like to cut right to the chase.
Voice AI has taken the world by storm in 2024, becoming one of the most compelling use cases for AI technology. When combined with text-based channels, the technology will quickly upend the $3T contact center industry enabling every interaction between businesses and consumers to be mediated by AI.
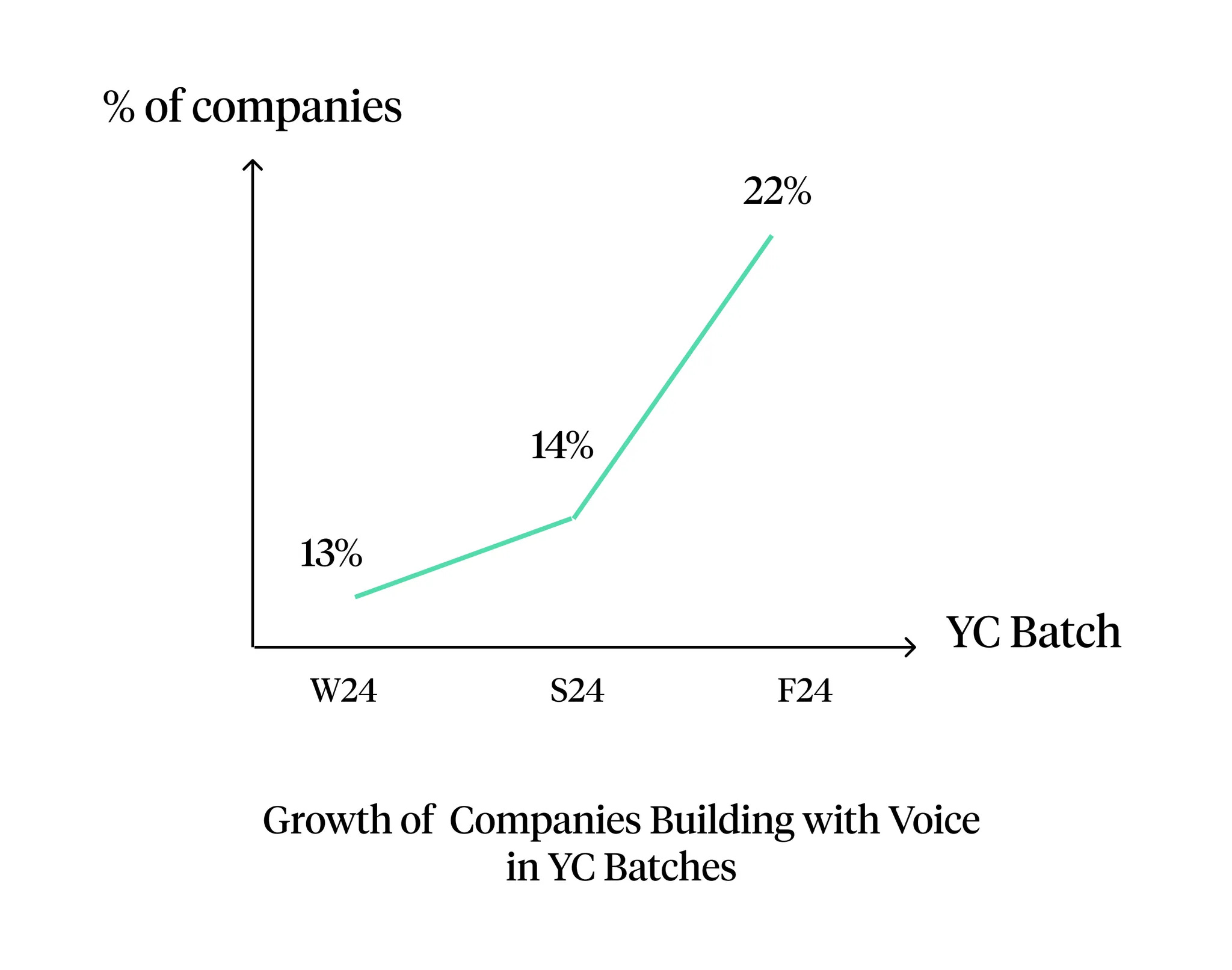
In the fall 2024 batch, 22% of YC companies in the latest batch are voice-native—a remarkable increase from just 6% a year ago. Large model labs have begun to invest significantly in this interaction platform, with OpenAI and Google DeepMind releasing real-time voice mode and Gemini Flash 2.0, respectively. Smaller labs like Eleven Labs and Cartesia are also investing significantly into powerful voice-native experiences, increasing the quality of voice native experiences built atop of their platforms.
Why Voice-to-Voice Models are the Next Frontier
In 2025, voice-to-voice models are emerging as a transformative technology in the field. Traditional voice pipelines rely on a sequence of speech-to-text, processing by a large language model (LLM), and text-to-speech synthesis. Like with any high-performance machine learning system, voice-to-voice allows practitioners to minimize the compounding error rate which can arise from a multi-model architecture. Voice-to-voice models have a few characteristics that drastically improve customer satisfaction over previous voice pipeline approaches.
Improved Accuracy for Critical Information
Traditional pipelines often falter when tasked with transcribing precise information like email addresses, phone numbers, or alphanumeric codes. These approaches require lightning-fast transcription models that often cannot grasp the broader context of what a user is saying. In contrast, speech-to-speech models, undergirded by a large language model (LLM), can intuit key transcription details more effectively, much like a human might when understanding speech. These challenges compound in languages with phonetic or tonal complexities, for which transcription data is scarce precluding agents from a wide set of use cases.
Reduced Latency and Simplified Infrastructure
By eliminating the need for multiple service calls—speech-to-text, LLM processing, and text-to-speech—voice-to-voice models drastically lower latency. This reduction is particularly important for real-time applications like customer support or conversational interfaces, where delays can degrade user experience. Additionally, this reduced latency simplifies infrastructure requirements; if you're only calling one model, you don't need to worry about collocating various steps of the voice pipeline.
Enhanced Conversation Satisfaction Through Mirroring
One of the most compelling advantages of voice-to-voice models is their ability to mirror a user’s speech patterns. This mirroring—whether through tone, pacing, or inflection—enables more natural and engaging interactions. Such capabilities are particularly valuable for use cases like sales, where building rapport is key, or in sensitive customer support scenarios, where empathy and understanding are critical. Voice-to-voice models retain nuanced elements of speech, such as emotion, tone, and prosody components which are all lost with traditional voice approaches.
Existing Limits to Voice-to-Voice
While voice-to-voice models offer transformative potential, there's a reason we don't see broader adoption of the approach in a number of production use cases.
Content Moderation: Content moderation remains a critical concern for enterprises adopting voice-to-voice models. Ensuring that speech outputs align with company guidelines or avoid inappropriate content is inherently challenging without a text intermediary. Companies like OpenAI have pioneered live content moderation solutions, transcribing real-time speech outputs to flag and halt inappropriate conversations immediately. In sensitive domains, like healthcare and law, voice agents need strict guardrails to restrict agents from dispensing medical advice or hallucinating company policies.
Reasoning/Speed Trade-offs: Voice agents have historically faced trade-offs between reasoning speed and accuracy, particularly in complex function calls or multi-step tasks. These capabilities are crucial for voice agents to replace agents in a variety of domains. However, current systems still grapple with delivering consistent logical coherence at real-time speeds.
Cost and Reliability: Until recently, cost has been a significant barrier for scaling voice-to-voice agents. For example, OpenAI’s real-time API historically cost $0.09 per input and $0.24 per output, amounting to nearly $9 per hour—comparable to a human call center agent in regions like the Philippines. This cost structure has limited widespread use, particularly for smaller businesses or organizations operating at scale.
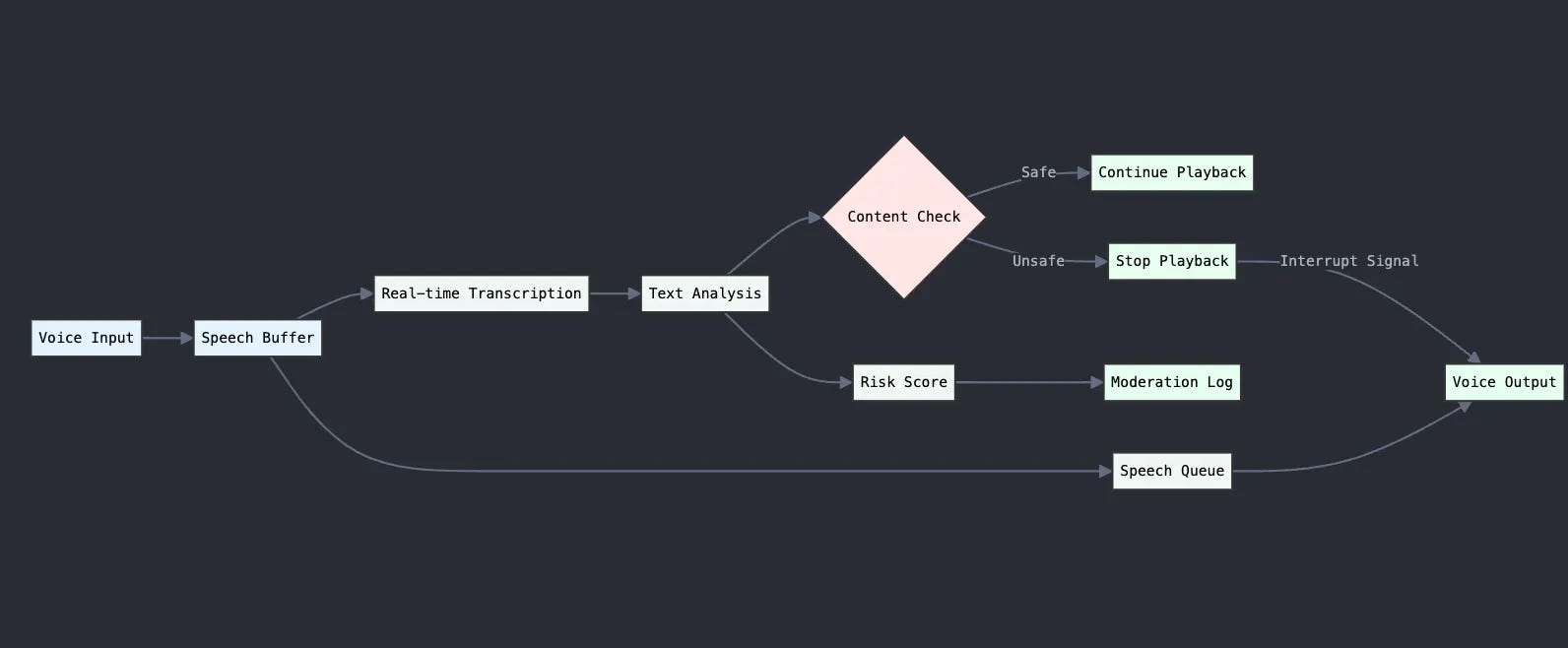
In 2025, however, there's definite optimism that many of these issues will be solved. Voice-to-voice content moderation is quickly becoming a solved problem, thanks to rapid and accurate transcription models. Real-time content moderation works by immediately stopping speech play-out if inappropriate content is detected. Companies like OpenAI implement this using transcription models in their advanced live mode and real-time API. As transcription models become faster, there is potential to introduce a voice-native moderation layer, enabling seamless and proactive moderation directly within the speech pipeline. Below is a brief diagram for how this is typically implemented.
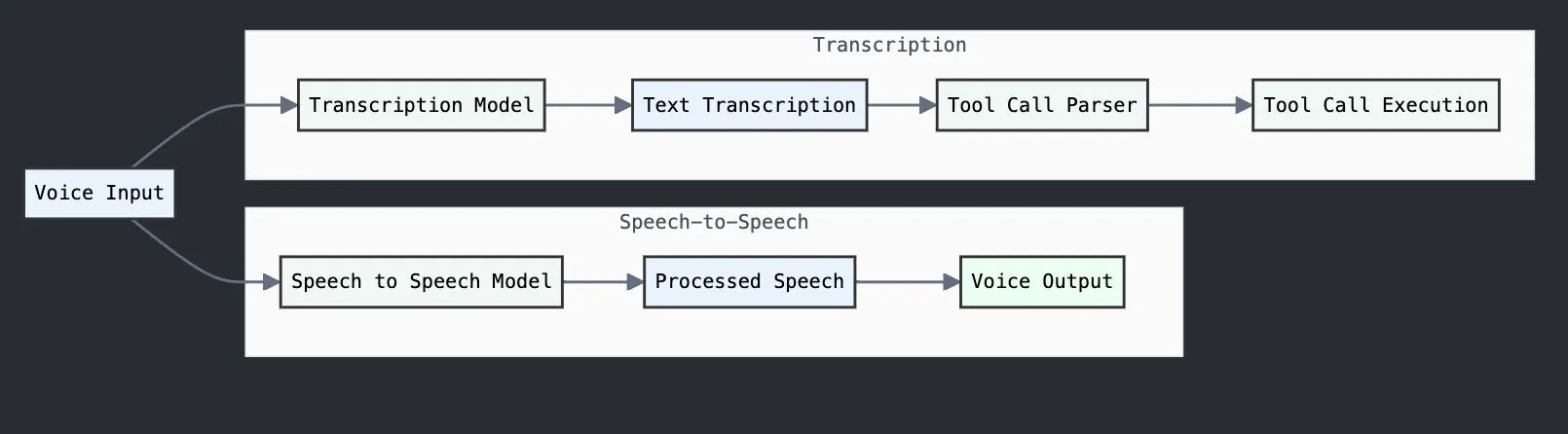
"Fundamental equations" balancing reasoning speed, cost, and realism have also transformed significantly towards the end of last year. Improved instruction-following performance in smaller models (such as Llama 3.3 70B and OpenAI's GPT-4o-mini) has unlocked new opportunities for voice-to-voice agents. These agents, built on platforms like OpenAI's realtime-mini or Fixie AI's Ultravox, demonstrate impressive capabilities in completing multi-step reasoning tasks. Parallel approaches used to disambiguate function calling and dialog enable agent builders to skirt this trade-off entirely.
Voice-to-voice models are coming down significantly. Competition between OpenAI's Realtime API and Gemini's Flash 2.0 model produces yet another win for builders at the application layer. The newest OpenAI Realtime-mini model now clocks in at an average hourly cost of 90 cents per hour, unlocking feasibility for voice for a number of high-volume use cases.
Looking Ahead
Voice-to-voice AI represents a pivotal advancement in the evolution of conversational technologies. By addressing challenges like content moderation, reasoning accuracy, and cost, these systems are paving the way for broader adoption across industries. The innovations seen in 2024 and 2025 have laid the groundwork for practical, scalable voice AI solutions, enabling applications from customer support to high-sensitivity domains like healthcare. As costs decrease and capabilities improve, voice-to-voice systems are no longer just a promising idea but a practical reality reshaping human-computer interactions. Organizations investing in this technology now stand to gain a significant edge as the field matures.